|
I am currently a researcher at Noah's Ark Lab, Huawei. Before joining Huawei, I recieved my Ph.D. degree from the Department of Electronic Engineering, Tsinghua Univerisity, and my bechalor's degree from the Department of Physics, Tsinghua University. During my Ph.D. time, I have been fortunate to work closely with Prof. Liang Zheng, Dr. Yifan Sun, Dr. Luca Bertinetto, and Prof. Hengshuang Zhao Email / CV / Google Scholar / Github |

|
|
In the long term, my research interest lies in developing general embodied intelligent agents (an autonomous driving car can be a simplified example). I have a faith that the emergence of general machine intelligence requires observing, interacting with, and learning from the physical world. In the future, embodied agents may be able to train themselves on the edge, and possibly explore the world in clusters, learning together to form a foundational intelligent model (somewhat like the Sibyl system in the Sci-Fi anime Psycho-Pass, but an enhanced version that can interact with the world). Such a strong intelligent model may looks a little bit evil, but with efforts I believe we can make it used for good purposes :) In the short term, my research interest lies in perception algorithms for automonous driving. Including but not limited to 2D/3D object detection, segmentation, tracking, 3D reconstruction, and offboard pereception (for auto-labeling). I have several openings for self-motivated reserach interns on these topics, please feel free to drop me an e-mail. Previously, I did research on representation learning and object tracking. Representative works include JDE and UniTrack for object tracking, the CycAs series [v1,v2,v3] for person re-identification, and Circle Loss, D-Softmax Loss for metric learning. |
|
|
Generative AI |

|
PixArt-alpha is the first DiT-based T2I diffusion model whose image generation quality is competitive with SoTA image generators (e.g., Imagen, SDXL, and even Midjourney), reaching near-commercial application standards. With efficient designs, our training only takes 10.8% of Stable Diffusion v1.5's cost in terms of GPU days. Many recent Text-to-Video models such like Latte, Open-Sora, Open-Sora-Plan are inspired by or built upon PixArt-alpha. |

|
An update version of PixArt-alpha that is capable of generating ultra-high resolution (up to 4K) images in super realistic quality. |
Perception (object detection/segmentation/tracking) |

|
By incorporating the appearance embedding model into the detector, we introduce JDE, the first open-source real-time multiple object trackor with a running speed of 22 ~ 38 FPS. This speed takes all the steps into account, including detection, appearance embedding extraction and association. Code is released! If you are looking for an easy-to-use and fast pedestrian detector/tracker, JDE is a good option! |
|
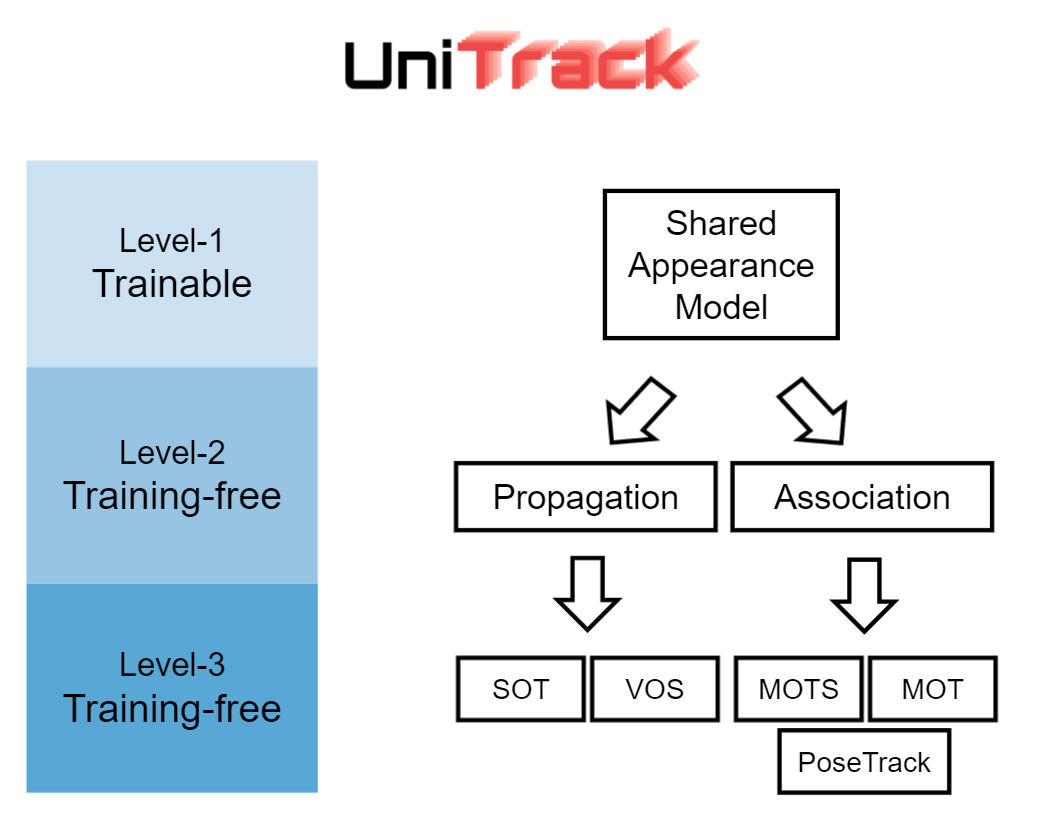
Object tracking has been fragmented into multiple different experimental setups due to different use cases and benchmarks. We investigate if it is possible to address the various setups with a single, shared apperance model. |
|
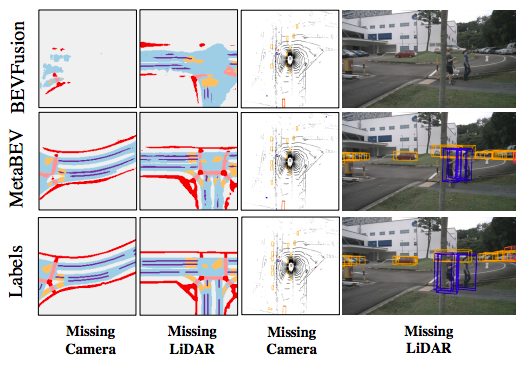
MetaBEV is a 3D Bird-Eye's View (BEV) perception model that is robust to sensor missing/failure, supporting both single modality mode (camera/lidar) and multi-modal fusion mode with strong performance. |
Representation learning / re-identification |
|
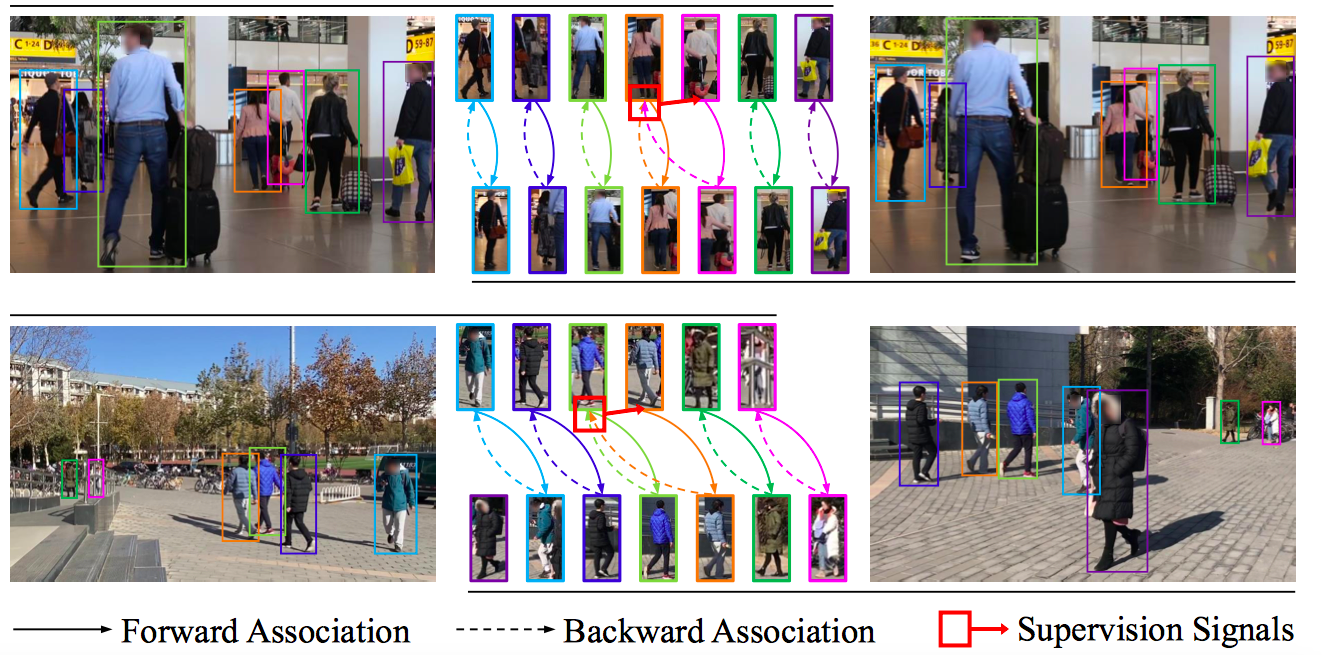
CycAs is the fisrt self-supervised method for learning re-identifiable features. We use videos as input, the supervision signal is cycle consistency emerging from instance association in a forward-backward cycle. In CycAs v1, we train and show promising results on (mostly small) canonical datasets; In CycAs v2, we collect a large amount of video data and train a much more generalizable model with improved building blocks. The zero-shot transfer ablility is suprisingly good, with a rank-1 accuracy of 82.2% on Market-1501. |

|
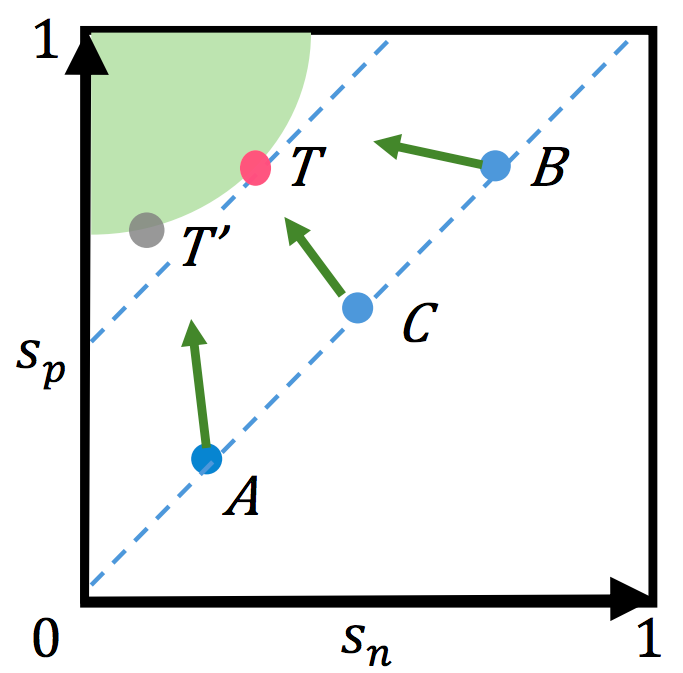
A new self-supervised learning objective further improves upon CycAs v2, refreshing the zero-shot transfer performance on Market-1501 to 87.1% rank-1 accuracy, already on par with supervised models trained with in-domain data. |
|
A unified perspective for proxy-based and pair-based metric learning. |
|
Self-supervised learning via Maximum Entropy Coding improves generalization ability of the learned representation on a variaty of down-stream tasks. |
|
(* Interns & Students, + Equal contribution) |
PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation
Junsong Chen*+, Chongjian Ge*+, Enze Xie+, Yue Wu+, Lewei Yao, Xiaozhe Ren, Zhongdao Wang, Ping Luo, Huchuan Lu, Zhenguo Li
ECCV, 2024.
Space-Correlated Transformer: Jointly Explore the Matching and Motion Clues in 3D Single Object Tracking
Fei Xie*, Jiahao Nie, Zhongdao Wang, Zhiwei He, Chao Ma
ECCV, 2024.
OccGen: Generative Multi-modal 3D Occupancy Prediction for Autonomous Driving
Guoqing Wang*, Zhongdao Wang, Pin Tang*, Jilai Zheng*, Xiangxuan Ren*, Bailan Feng, Chao Ma
ECCV, 2024.
VEON: Vocabulary-Enhanced Occupancy Prediction
Jilai Zheng*, Pin Tang*, Zhongdao Wang, Guoqing Wang*, Xiangxuan Ren*, Bailan Feng, Chao Ma
ECCV, 2024.
LogoSticker: Inserting Logos into Diffusion Models for Customized Generation
Mingkang Zhu*, Xi Chen, Zhongdao Wang, Hengshuang Zhao, Jiaya Jia
ECCV, 2024.
Segment, Lift and Fit: Automatic 3D Shape Labeling from 2D Prompts
Jianhao Li*+, Tianyu Sun*+, Zhongdao Wang, Enze Xie, Bailan Feng, Hongbo Zhang, Ze Yuan, Ke Xu, Jiaheng Liu, Ping Luo
ECCV, 2024.
SparseOcc: Rethinking Sparse Latent Representation for Vision-Based Semantic Occupancy Prediction
Pin Tang*, Zhongdao Wang, Guoqing Wang*, Jilai Zheng*, Xiangxuan Ren*, Bailan Feng, Chao Ma
CVPR, 2024.
DiffusionTrack: Point Set Diffusion Model for Visual Object Tracking
Fei Xie*, Zhongdao Wang, Chao Ma
CVPR, 2024.
PixArt-α: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
Junsong Chen*+, Jincheng Yu*+, Chongjian Ge*+, Lewei Yao*, Enze Xie, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo Huchuan Lu, Zhenguo Li
ICLR, 2024. (Spotlight)
Unsupervised Temporal Correspondence Learning for Unified Video Object Removal
Zhongdao Wang, Jinglu Wang, Xiao Li, Ya-Li Li, Yan Lu, Shengjin Wang
IEEE Transactions on Image Processing (TIP), 2024.
MetaBEV: Solving Sensor Failures for BEV Detection and Map Segmentation
Chongjian Ge*+, Junsong Chen*+, Enze Xie, Zhongdao Wang, Lanqing Hong, Huchuan Lu, Zhenguo Li, Ping Luo
ICCV, 2023.
Identity-Seeking Self-Supervised Representation Learning for Generalizable Person Re-identification
Zhaopeng Dou*, Zhongdao Wang, Yali Li, Shengjin Wang
ICCV, 2023. (Oral)
Self-Supervised Learning via Maximum Entropy Coding
Xin Liu*, Zhongdao Wang, Yali Li, Shengjin Wang
NeurIPS, 2022. (Spotlight)
Reliability-Aware Prediction via Uncertainty Learning for Person Image Retrieval
Zhaopeng Dou*, Zhongdao Wang, Weihua Chen, Yali Li, Shengjin Wang
ECCV, 2022.
How to Synthesize a Large-Scale and Trainable Micro-Expression Dataset?
Yuchi Liu*, Zhongdao Wang, Tom Gedeon, Liang Zheng
ECCV, 2022.
Progressive-Granularity Retrieval Via Hierarchical Feature Alignment for Person Re-Identification
Zhaopeng Dou*, Zhongdao Wang, Yali Li, Shengjin Wang
ICASSP, 2022.
Adaptive Affinity for Associations in Multi-target Multi-camera Tracking
Yunzhong Hou, Zhongdao Wang, Shengjin Wang, Liang Zheng
IEEE Transactions on Image Processing (TIP), 2021.
Do Different Tracking Tasks Require Different Appearance Models?
Zhongdao Wang, Hengshuang Zhao, Ya-Li Li, Shengjin Wang, Philip HS Torr, Luca Bertinetto
NeurIPS, 2021.
CycAs: Self-supervised Cycle Association for Learning Re-identifiable Descriptions
Zhongdao Wang, Jingwei Zhang, Liang Zheng, Yixuan Liu, Yifan Sun, Yali Li, Shengjin Wang
ECCV, 2020.
Towards Real-time Multi-object Tracking
Zhongdao Wang, Liang Zheng, Yixuan Liu, Yali Li, Shengjin Wang
ECCV, 2020.
Rank 15th in most influential ECCV 2020 papers
Circle loss: A unified perspective of pair similarity optimization
Yifan Sun, Changmao Cheng, Yuhan Zhang, Chi Zhang, Liang Zheng, Zhongdao Wang, Yichen Wei
CVPR, 2020. (Oral)
Softmax Dissection: Towards Understanding Intra-and Inter-class Objective for Embedding Learning L He, Z Wang, Y Li, S Wang
Lanqing He+, Zhongdao Wang+, Yali Li, Shengjin Wang
AAAI, 2020. (Oral)
Linkage based Face Clustering via Graph Convolution Network
Zhongdao Wang, Liang Zheng, Yali Li, Shengjin Wang
CVPR, 2019.
Orientation Invariant Feature Embedding and Spatial Temporal Regularization for Vehicle Re-identification
Zhongdao Wang+, Luming Tang+, Xihui Liu, Zhuliang Yao, Shuai Yi, Jing Shao, Junjie Yan, Shengjin Wang, Hongsheng Li, Xiaogang Wang
ICCV, 2017.
|
Design and source code modified based on Jon Barron's website. |